人工知能(A.I.)の講義ノート(後編)
<具体的な機械学習の分類>
AIを活用するにあたり2つのステップがある。1つ目のステップは、画像や音声などの私たちが普段接している情報をコンピュータに読み込ませるために数字の羅列のような形式である「特徴量」と呼ばれるものに変換すること。例えば、画像であればピクセルごとの色情報(RGBであれば0〜255のどれか)として表現することができる。2つ目のステップは、その特徴量を使って分析・学習するというデータ処理のプロセスである。ディープラーニングの誕生によって、これらのプロセスは連続かつ同時に行われるようになってきたが、分かりやすいため別々に説明したい。
<ステップ1:特徴量の抽出>
ステップ1はデータから特徴量を抽出する作業が必要であった。その前に、まずは我々が扱うデータの種類についてしっかりと把握しておく必要がある。大きくは「量的データ」と「質的データ」に分類できる。
| データの種類 | 尺度の種類 | 具体例 |
|---|---|---|
| 量的データ:(演算ができるもの) | 比例尺度:数字の比率に意味があるもの。ゼロが何も存在しないということを意味するもの。 | 身長、体重、速度、金額 |
| 〃 | 間隔尺度:数字の間隔に意味のあるもの。ゼロの1つの状態と考えられるもの。 | 試験の点数、時刻、年齢 |
| 質的データ:(分類や種類を区別するためのもの) | 順番尺度:分類の順番に意味があるもの | 度数、順位、満足度、アンケートの5段階評価 |
| 〃 | 名義尺度:分類の順番に意味のないもの | 性別、血液型、携帯電話番号 |
扱っているデータがどんなデータなのかを把握しておかないと、本来はできないのにデータ同士で演算(足し算や引き算など)してしまったりする可能性があるので注意が必要である。なお、「質的データ」は基本的に演算できないため、ダミー変数で量的データに変換してコンピューターに読み込ませる必要がある。
さていよいよデータから特徴量の抽出する作業となる。特徴量とは「対象とする事物の特徴を定量的に表した変数」であり単に特徴とか特徴ベクトルと言ったりもする。例えば「自動車」をコンピューターに認識させるためには、形、色、材質など様々な特徴量が必要になる。特徴量が3つの場合、特徴量は3次のベクトルで表現され、a=(◯、◯、◯)のような形式となる。◯の部分には数字が入る。通常は特徴ベクトルは3次元以上の高次元となるため人間ではなかなかイメージできないが、特徴量が高次元であるからこそ、無数に存在する物体の中から「自動車」のような特定の物体をコンピューターが識別できるようなる。
<ステップ2:分析・学習>
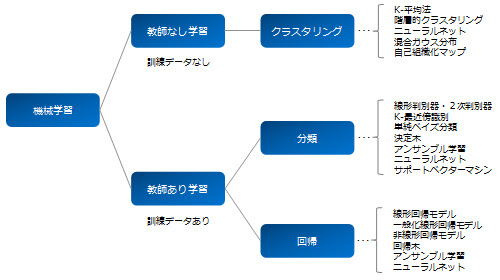
ステップ2の分析・学習については、「問題設定の方法による分類」や「アルゴリズムによる分類」が可能である。まずは前者による分類には主に以下の3つがある。①教師あり学習、②教師なし学習、③強化学習である。なお、処理するアルゴリズムについては詳しくは後述するが、どれだけ優れたアルゴリズムを使っているかというよりは、「どれだけ濃密な顧客の嗜好データや購入履歴を入手しているか」、あるいは「いかにベストな特徴量の設定をしているのか」の方が認識精度に直結する重要な要素である場合が多い。そのためビジネス的観点からはアルゴリズムについては必ずしも内容を深く理解していなくても大丈夫そうである。逆に、ビジネスでは豊富なデータこそが企業のアセットであり「差別化の源泉」になっていると考えられる。例えば、FacebookやGoogleは膨大な顧客情報を得ている会社の典型例である。以下、①教師あり学習、②教師なし学習、③強化学習についてそれぞれ説明していきたい。なお、ここでは既にステップ1の「特徴量」が得られているという前提で説明していく。
①教師あり学習
まず「教師」というのは「正解」という意味であり、教師あり学習(「ラベル付きデータ」や「正解付きデータ」などとも呼ばれる)というのは、正解が既知である無数のデータセットに基づき、コンピューターに学習させていく方法である。例えば、山の写った写真を読み込ませる際、これは山であるという正解情報も併せて入力する。そうするとコンピューターは次第に学習し、正解のない新しい写真を見せても自動的に山であると判断できるようになっていく。最終的な出力の種類は、大きくは「分類」「回帰」に分類できる。「分類」とは例えば0〜9までの中でどの数字か、あるいは山か海かなどのカテゴリーのことであり、回帰とは33.5などの実数を扱うことになる。
②教師なし学習
これは「教師がない」つまり正解が与えられていないデータを元に学習していくものを指す。そもそも正解が存在しない問題やコンピューターに何かしらの方法で結果を分類してもらいたい場合などに用いられる。よく使われる考え方として「クラスタリング」がある。
クラスタリング:コンピュータが様々な特徴などから、結果を複数の種類やカテゴリー群に分類するもの。ただし最終的にその群がどのような意味を持つのかは人間が判断しないといけない。例えば、顧客セグメント分けなどに使われる。そのためのアルゴリズムとして有名なものに「K平均法」がある。これは最初ランダムにクラスタを設定し、その後クラスタごとに重心からの距離を計算し、その距離が最も小さくなるようクラスタ分けを繰り返して、最終的なクラスタを探していくもの。なお、クラスタ数自体は最初に人が決める必要がある。また「次元削減」のため、前処理として活用される場合もある。
③強化学習
事前にデータセット自体が与えられない場合の学習方法であり、コンピューターにある種の「試行錯誤」をさせて正解を見つけられるようにしていく学習方法である。例えば、スキーで倒れずにゴール地点までにたどり着く方法を学習させたいとする。その際まずは「報酬」を設定する。例えば、下まで早くたどり着けたら加点するとか、倒れずに行けたら加点する(倒れたら減点でもよい)など。その上で、コンピューターにひたすら試行錯誤させていくと、最初にどういった滑り方が正解なのかという情報を与えていないにも関わらず、徐々に報酬を高くなる最適な滑り方を習得していくイメージになる。

出典:クックパッド開発者ブログ、http://techlife.cookpad.com/entry/2014/10/29/102036
同じような考えだが、有名なものに「多腕バンディット問題」というものがある。バンディットとはスロットマシンのこと。仮に3つのマシンがあったとして、1000回スロットルを引けるとする。3台の当たりが出る確率は0.2、0.3、0.4と予め決まっているが、勿論コンピューターにはその確率は知らなせない。この状況下で最大の報酬を得るには、どのようにスロットマシンを引けばいいのかいう問題だ。ランダムに1つのマシンを選び、確率0.2のスロットマシン1000回引いた場合、報酬は最低になる。一方、確率0.4のスロットマシンだけを引いた場合は報酬は最大になるが、これではただの運任せである。そこで、最初に3台ともまずは引いてみて当たりが出そうなマシンを探す。これが「探索」と呼ばれる作業。そしてその結果を基に一番当たりが出そうなマシンを引く回数を上げていく。これを「活用」と言います。これを処理するアルゴリズムとして「Greedy」や「ε-Greedy」、「softmax」、「UCB」などがある。詳しい説明は割愛するが、とにかく強化学習は実社会の問題に解決方法に似ている面がある。実社会でも、結果が黒か白か正解は分からないけど、とにかくまずは試行してみて、その中で正解を探していくイメージである。
<分析・学習のためのアルゴリズム>
ここでは最もよく使われている「教師あり学習」のアルゴリズムについて少々みていく。教師あり学習は「分類」と「回帰」に分類できたわけだが、まず分類を実行するための一般的なアルゴリズムには、線形分類器、k 最近傍法 、単純ベイズ、決定木、アンサンブル学習、ニューラルネットワーク、サポートベクターマシン(SVM)などがある。一方、回帰のためのアルゴリズムには、線形回帰、非線形回帰、正則化、ステップワイズ回帰、決定木、 ニューラルネットワーク、適応ニューロファジー学習などがある。なお、アンサンブル学習とは、単純モデルなどを複数組み合わせて最適なモデルをつくる考え方である。
出典:MathWorks、「機械学習とは」https://jp.mathworks.com/discovery/machine-learning.html?s_eid=PSM_5572
ここでは一番単純で代表的な「線形分離(判定)器」について説明していきたい。そのアルゴリズムを式で表すと以下のようになる。
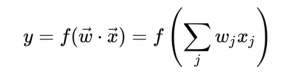
ここで、特徴ベクトルが xで表され、wは重み付けの実数ベクトルを表している。重み付けベクトル wは教師あり学習で随時変化していく。関数を表すf は2つのベクトルの内積を出力する際の何かしらの関数である。例えば、内積の和がある閾値以上の値を第一クラスに分類し、それ以外を第二クラスに分類するといった単純な関数であることが多い(二項分類)。なお実際には特徴ベクトルは3次元以上の多次元ベクトルである場合がほとんどなので、高次元空間になればなるほど、特定の領域を閾値で特定することが十分可能になっていくイメージである。
このアルゴリズムはとても簡単かもしれないが、まずはこれで試して学習精度が高くならないものは、複雑なアルゴリズムを使ってもダメらしい。そのためまずはこれをしっかり理解することが重要だ。
<ディープラーニングとは>
①ディープラーニングの仕組み
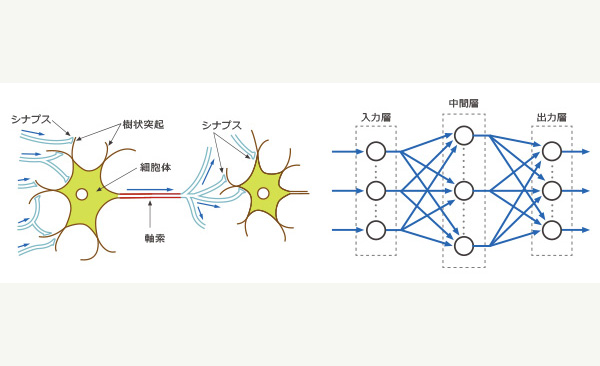
デープラーニングとは、機械学習の一部であり、人の脳の神経細胞の仕組みにヒントを得た「ニューラルネットワーク」を使った学習方法。ただしデープという名の通り、3層以上の深い階層を持つニューラルネットワークを使用していることが特徴。ただし、「人の脳の神経細胞」といっても、あくまでその一部の仕組みを模倣しているに過ぎず、基本的には人間の脳とはほぼ無関係と考えて良い。
出典:株式会社ALBERT、ディープラーニングとは、https://www.albert2005.co.jp/knowledge/machine_learning/deep_learning/about_deep_learning
② なぜ今ブレイクしているのか?
実はニューラルネットワークの考え方自体は、1963年に既に確立し、その後AIと同様第一次ブームを迎えるものの、様々な問題に直面しブレイクできなかった。第二次ブームの頃には、多層パーセプトロン(入力、中間、出力の2層のニューラルネットワーク)の基礎を担う要な手法として、「誤差逆伝播法」や「確率的勾配法」が開発された。しかし「ディープ」ラーニングのように更に多層化すると、パラメータを最適化するときに「勾配消失や爆発(発散)する問題」や「過学習しやすい問題」に直面し、第二次ブームもその後冬の時代を迎えることになった。なお「過学習」とは、与えられた(ノイズを含む)データに過度に適合してしまい、訓練誤差は小さいが未知のデータに対する性能が低下してしまう問題である。しかし2012年の冬、ヒントン教諭は、ILSVRCと呼ばれる画像認識の競技会で研究成果を発表して以来大きなブレイクが起きた。ディープラーニングがブレイクしたのは、ヒントン教授を中心とした学術的進展の他にも、周辺の技術的進展によるところも大きい。これは既に述べたものとも重なるが、①整備されたデータの増加(ビックデータ)、②計算機の性能向上(GPU=画像演算=行列の計算が得意)などである。
更にこれが実社会に影響を与えると思われる理由は大きく2つある。「クラウド環境の普及」と「オープンな研究開発の文化」である。
1)クラウド環境の普及
今まではサーバーなどの大がかりでコストも高いインフラを設置する必要があったが、今では2014年にMicrosoftの「Azure Machine Learning」や「Watson on Bluemix」、2015年には「Amazon Machine Learning」などのクラウド環境が急速に整備された。またすぐに使えるテンプレート(API)が用意されているので、かなり簡単に使うことができる。さらにまた費用は基本的には「使った分だけ」であり初期費用がほぼゼロから試してみることができる。詳しくは「実装の選択肢」でも述べる。
2)オープンな研究開発の文化
これはこのAIの研究および会社での特異的な文化でもあるが、最先端の研究内容が全て公開されていることである。普通の研究開発では最新の技術は特許で保護するなどいかに情報を守るかということに注力しているわけだが、この分野に限っては「公開は当然」という文化があり、逆に公開していないと優秀な人材が集まらないなどマイナスの効果の大きい。例えば、Matlab は非常に有名な数値解析ソフトウェアであり、その中で使われるプログラミング言語の名前でもある。しかし、アルゴリズムの内容が公開はされておらず非常の高価である。一方、Pythonは完全なオープンソースであり何より無料で提供されている。今でも多くの人がPythonを使っているのが現状である。また会社レベルでは原則非公開としているAppleと、公開するGoogleとの違いが鮮明になっている。Appleでは優秀な技術者の人材確保が難しくなり、最近ではオープンな風土への変革に取り組んでいるようである。このように誰でも最新の情報にアクセスできることが、研究開発や技術開発を加速させている理由となっている。
③ディープラーニングの限界
もはや一時的なブームではなくブレイクしたと言われるディープラーニングであるが、それでも現時点ではその適応範囲はかなり限定的と言わざるを得ない。今特に活用されているには、「画像分析」など一部の分野である。その他の分野では普通の機械学習の方が優れている場合も未だ多い。また画像分析でも実際のビジネスで使われるレベルにあるのは、GoogleやAmazonなど超大手企業などほんの一部の会社である。ディープラーニングのためには「整備された大量のデータ」が鍵であるが、それが確保できる分野はかなり限られていることも理由である。またディープラーニングには確かに以前まで人間が設定していた特徴量を自動的に抽出できる特徴を有するものの、複雑なモデルがゆえ、人間が設定しなければいけない「ハイパーパラメータ」と呼ばれるパラメータも多いことも理由である。例えば、多層のニューラルネットワークの「層の数」「繋ぎ方」「各階層での特徴量の数」などは人間が決定する必要があり、またそのためには膨大なノウハウが必要である。このあたりの分野は未だ大学などでの研究段階といえる。あまり過度に「ディープラーニングができれば何でもできる!」とか「強いAIができる!」と考えるのには時期尚早という状態である。
<ディープラーニングで有名なモデル>
①CNN (Convolution Neural Network)
CNNは折り込み層とプーリング層を交互に重ねて構成されたニューラルネットワークのこと。詳細は割愛するが、層を追うごとに小さなパーツから大きなパーツへと特徴を構成していくようにニューロンの結合強度が変化していくものである。現在、画像処理の問題ではCNNを使うことが一般的になっている。
②RNN (Recurrent Neural Network) :再帰型ニューラルネット
例えば文章を理解するときには、単語や一文だけ理解するだけでは不十分であり、前の文章の流れを次の文章の理解に反映させることが必要である。このように連続的な文章の分析などで使われるのがRNNである。
<実装の選択肢>
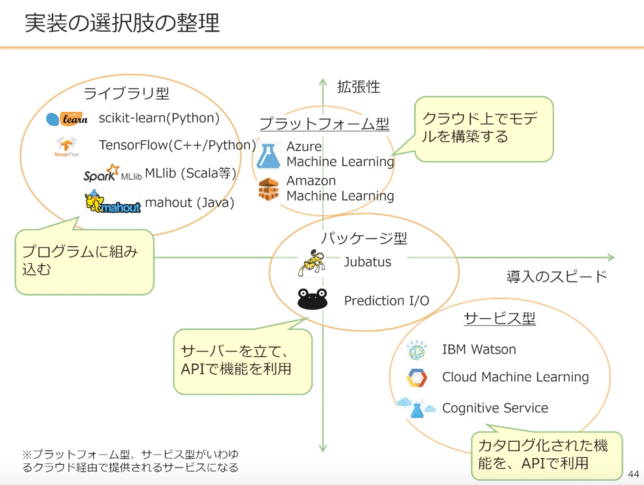
さて次に機械学習を実際に使うにあたって、どのような選択肢があるのか見てみよう。「実装のスピード(簡単さ)」と「拡張性」という軸で大きくは4つに分類できる。左上から「ライブラリ型」「プラットフォーム型」「パッケージ型」「サービス型」である。ライブラリ型の特徴は自分自身でプログラミングを書く必要があること。もちろんそれゆえ拡張性は高いが導入のスピードが遅くなりがちだ。プラットフォーム型とパッケージ型は非常に似ているが、前者はクラウド上でモデル構築できる一方、パッケージ型は自分でサーバーを立てる必要がある。一番実装のスピードが早いのがサービス型であり既に用意されたAPIを活用できる一方、内容を変更することはできない。拡張性と導入のスピードは基本的にトレードオフの関係にあるため、自分が求めるレベルを見極めて何を使って実装するのか考えたい。
出典:Udemyの「アプリケーション開発者のための機械学習」を受けてみた、http://okatenari.com/2017/12/21/ml-app/
なお、Pythonで自らプログラミングする人のために、これだけは知っておきたいライブラリを列挙しておく。①-scipy(科学)②-numpy(行列)、③-pandas(データフレーム・表)、④-scikit-learn(学習機械)、⑤-matplotlib(グラフの可視化)、⑥-seaborn(グラフの可視化)である。
<AIの三人のキーパーソンと重要な国際会議>
AIやディープラーニングは「前編」で述べた通り、過去に大きな2つのブームとその失敗を経験してきた。そんな中今3つ目のブームそしてそれがブレイクに繋がったのは冬の時代でもあっても途絶えることなく研究を続けてきた研究者たちの努力の賜物である。その中でも最も有名な3名が①AIの生みの親と言われる「ジェフリー・ヒントン」現在はトロント大学、また Googleが研究室ごと買収したため現在はGoogleにも所属。②「ヨシュア・ベンジオ」現在はモントリオール大学のLISA LABを率いている。また、IBMのワトソン共同研究を行なっている。③「ヤン・ルカン」現在はニューヨーク大学に勤務。Facebookにも所属している。その他Stanford大学の「アンドリュー・ング」も極めて有名であり、オンライン教育システムCouseraの設立をDaphne Kollerと一緒におこなっている。教授の講義はインターネットで公開されている。日本では、本サイトで何度か参照した東京大学の「松尾豊」が有名である。
さて、AIの分野では、最新の研究であっても全て公開する文化が成熟している。研究者や最先端の専門家にとって、国際会議で発表することが目標になっていて、有名なものに、NIPSやニューラルネットワークの国際会議などがある。各分野ごとに様々な会議があり下図がとても参考になる。
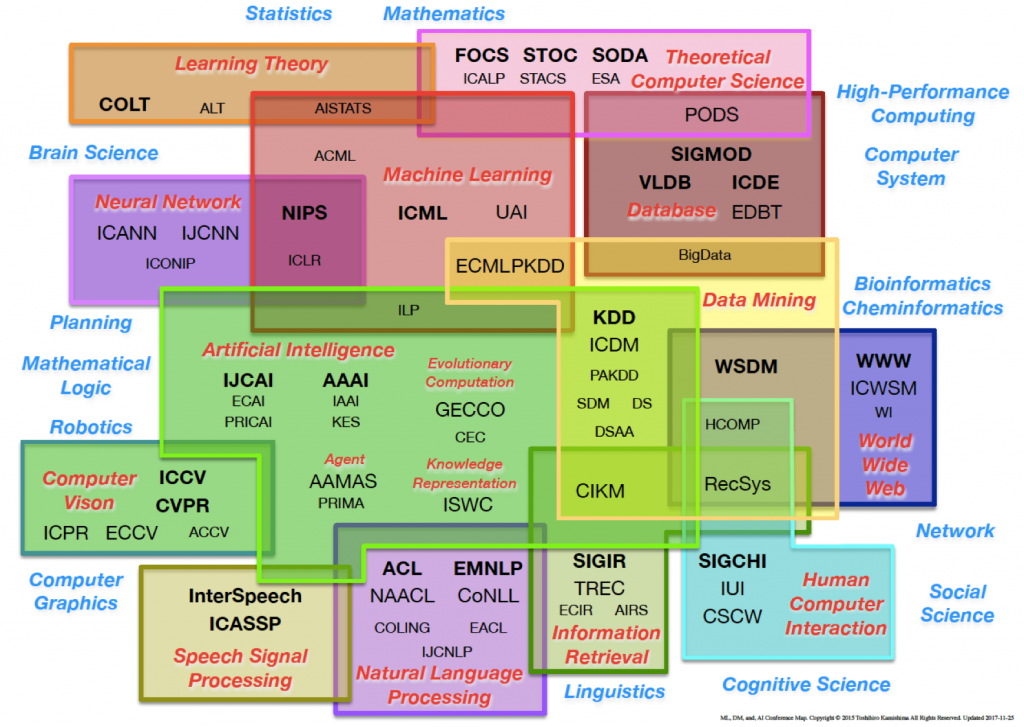
出典:http://www.kamishima.net/soft/
本当はこれ以外にも習ったことは幾つかあるのですが、基本的な内容として「講義ノート」にまとめるのはここまでにしようと思います。
最後に東京大学に在籍している山元 浩平先生の講義について少々。私が参加したAI Dojoというコースでは週末2日間のみ朝9時から夜7時までと大変タイトなコースながら、AIについて最低限知っておくべき全容が凝縮された講義であり、特に時間のない社会人には最適です。また何より少人数で先生との距離が近いため、分からないことは即座に質問でき、また先生も全く嫌がらず誠実にお答えいただけました。授業の方針も、ただ一方的に授業をして終わりではなく、「自分の言葉で説明できるようになること」を目標としており、「会社に戻って何ができるか」、自分たちで考える時間も用意されており、AIを身近に考える大きなきっかけになりました。このサイト上でも改めて感謝を申し上げたいと思います。別に宣伝ではないのですが、本当にオススメだと思います。また講義を一緒に受けたメンバーや他の会でのメンバーとも情報交換し、お互い高め合えれれば幸いです。
AI DOJO: https://aidojo.tokyo
AI HUB (Facebook): https://www.facebook.com/groups/ai.hubb/
